

Makine Öğrenimi (ML), karar verme ve tahminlerin akıllı insan davranışını taklit etmek için algoritmalar kullanarak bir bilgisayarın verilerden öğrenme yeteneği olarak tanımlanan Yapay Zekanın (AI) bir alt kümesidir.
Makine öğreniminde üç ana algoritma grubu vardır:
Denetimli (Supervised) Öğrenme,
Denetimsiz (Unsupervised) Öğrenme,
Pekiştirmeli (Reinforcement) Öğrenme
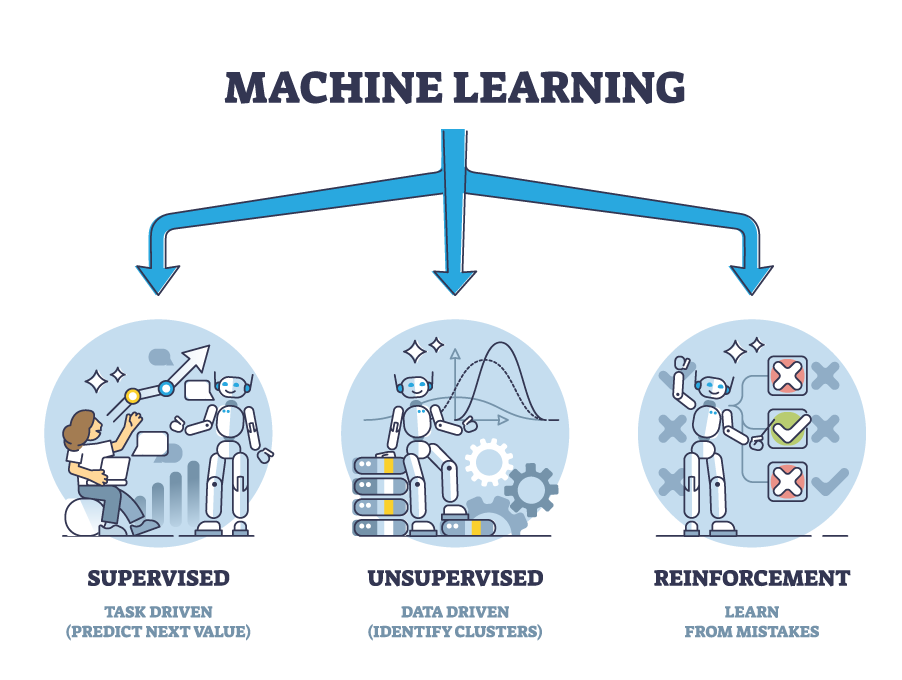
Denetimli Öğrenme
Eğitim verilerinden, öngörülemeyen verileri tahmin etmenize yardımcı olmak için öğrenen bir algoritmadır. Genellikle harici bir gözetmen, konu uzmanı veya bir algoritma/program tarafından etiketlenen bir veri kümesi kullanır. Tahmin etmeye çalıştığınız çıktı için bilinen verileriniz varsa denetimli öğrenmeyi kullanabilirsiniz.
Denetimsiz Öğrenme
Kullanıcıların modeli denetlemesi gerekmeyen bir makine öğrenimi tekniğidir. Bunun yerine, daha önce tespit edilmeyen kalıpları ve bilgileri keşfetmek için modelin kendi başına çalışmasına izin verir. Esas olarak etiketlenmemiş verilerle ilgilenir. Denetimsiz öğrenme algoritmaları, denetimli öğrenmeye kıyasla daha karmaşık işleme görevleri gerçekleştirmenizi sağlar.
Denetimli Öğrenme ve Denetimsiz Öğrenme Arasındaki Fark
- Denetimli Öğrenme algoritmasındaki en önemli nokta etiketli bir veri kümesi kullanılmasıdır. Yani hangi verinin hangi bilgiye karşılık geldiği bilindiğinden bilinen bir girdi seti ile bunlara denk gelen çıktıları alıp algoritmanın daha önce hiç görmediği (eğitimde kullanılmayan) yeni verilere en uygun çıktıları üretmek için kullanılan bir makine öğrenmesi modelidir.
- Denetimsiz Öğrenmede ise etiketsiz veriler vardır. Bu etiketsiz veriler arasındaki gizli kalmış yapıyı/örüntüyü bulmaya çalışarak kendi kendine öğrenme biçimi sergilenir.
- Denetimli öğrenme genellikle Regresyon ve Sınıflandırma problemlerine uygulanırken, denetimsiz öğrenme Kümeleme (Clustering) ve İlişkilendirme (Association) problemlerine uygulanır.
Pekiştirmeli Öğrenme
Amaca yönelik ne yapılması gerektiğini öğrenen bir makine öğrenmesi yaklaşımıdır. Pekiştirmeli öğrenmede ajan (agent) adı verilen öğrenen makinemiz karşılaştığı durumlara bir tepki verir ve bunun karşılığında da sayısal bir ödül sinyali alır. Daha sonra ajan deneme yanılma yoluyla bu ödül puanını maksimuma çıkartmak için çalışır.


